作者:顾静(子白)|阿里云高级研发工程师;谢瑶瑶(初扬)|阿里云技术专家
导语: 随着云原生理念在企业中的深入和践行,应用容器化的比例大幅提升。是否可以保证应用容器化迁移过程中的平稳切换,保证应用不停机迁移,成为影响用户业务云化的一个重要条件。本文整理自阿里云云原生团队在 KubeCon China 2021 线上峰会的分享实录,将通过集群迁移的需求、场景以及实践方式,介绍如何基于阿里云容器服务 ACK,在零停机的情况下迁移 Kubernetes 集群。
大家好,我是谢瑶瑶,来自阿里云,目前是 Cloud-provider 开源子项目 cloud-provider-alibaba-cloud 项目的 Maintainer。今天由我和我的同事顾静一起为大家分享如何不停机的迁移 Kubernetes 集群。顾静同学也是 cloud-provider-alibaba-cloud 项目的 Maintainer。

我们将从上图几个方面来分享如何不停机的迁移 Kubernetes 集群。首先我们会为大家介绍一下集群迁移的需求以及应用场景;接着我们会着重介绍如何实现不停机地 Kubernetes 集群迁移,包括如何进行迁移前的前置检查,如何做应用的数据迁移与流量迁移等等。

为什么要迁移 Kubernetes 集群?
下面简单介绍下集群迁移的应用场景。
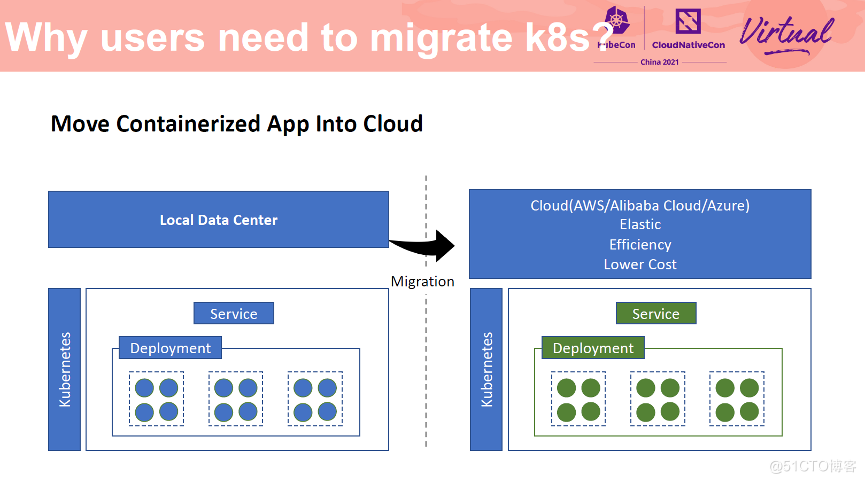
容器化的应用迁云
首先我们来看一下容器化的应用迁移场景。近年来云原生理念已经逐渐深入到了各大公司中。据相关调查统计,将近有 65% 的应用已经实现了容器化,并逐步从线下的数据中心迁移到了云上,以便充分利用云的弹性来实现企业的降本增效。是否可以保证应用容器化迁移过程中的平稳切换,保证应用不停机迁移,成为影响用户业务云化的一个重要条件。
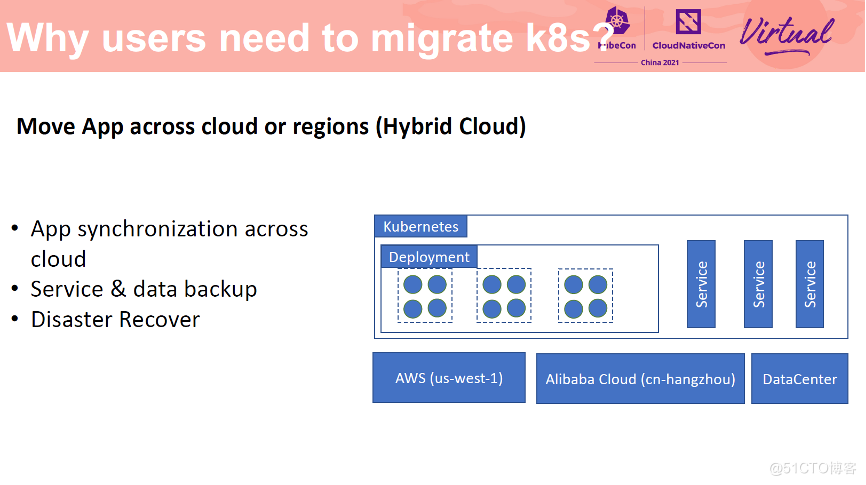
跨云同步与迁移
其次是混合云场景下的跨云流量迁移。对用户来讲,如果云是一个极具性价比的选择的话,那么混合云和多云的架构进一步为用户提供了一个低成本全球可达的应用发布平台。多云可以让用户的应用部署到多个云厂商,避免厂商锁定。同时它能够提供更高的议价能力、更强的备份、灾难恢复能力和更强的稳定性。同时还可以为全球用户提供基于地理位置的就近服务体验。如何进行不停机跨云同步机迁移是部署跨云/多云应用的前提。
集群新特性与 BreakingChange 场景
更高的 Kubernetes 版本往往会具有更多的新特性,但是使用这些新特性并不是没有代价的。如果你需要使用新特性,那就必须升级 Kubernetes 到对应的新版本。这通常不是一件容易的事情。如果你的集群版本太低,那么你需要多次升级集群才能到达预期的版本。比如从 1.14 依次升级到 1.16,然后是 1.18,然后才是 1.20,这样来避免单次升级集群版本过大造成的兼容性问题。并且这些新特性所引入的兼容性问题还可能造成服务中断。
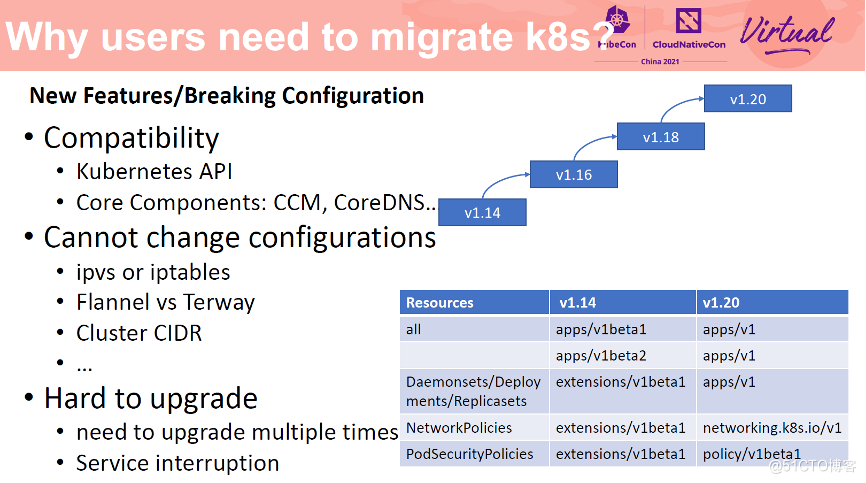
除了升级困难以及版本兼容性问题,升级已有集群无法实现一些配置变更类的需求。比如你无法直接变更一个已有集群的网络模式,比如从 IPTables 切换到 IPVS,Flannel 到 Terway,更改 Cluster CIDR 等。这些变更会造成整个集群已有节点及 Pod 的重建,造成服务不可用,甚至是整个集群配置被污染。因此不停止迁移 Kubernetes 集群应用在这种情况下可能是一个更好的选择。
接下来我们介绍一下如何进行不停机迁移。不停机迁移总体上分为 3 个阶段。
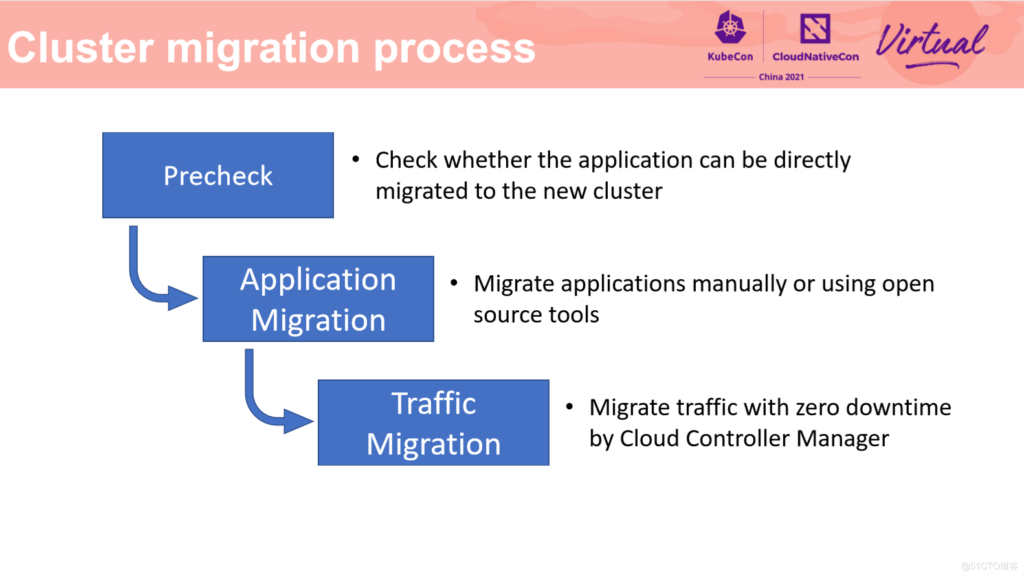
第一阶段:前置检查,提前暴露迁移可能存在的潜在风险;第二阶段是应用迁移,这一阶段需要新建一个目标版本的集群,并将应用及其数据迁移到新的集群中;第三阶段是流量迁移,这一阶段至关重要,他决定了如何不停机地将线上流量导入到新建的集群中,并使用新建的集群为用户提供服务。
首先在前置检查阶段,我们需要尽早的暴露迁移风险,因此我们开发了一套前置检查框架,用来检查集群是否做好了迁移准备。比如不同版本的集群会有 API groups 兼容性,需要提前处理 Label 的兼容性,不同版本的组件的行为差异等,如 kubeproxy 处理 SLB 流量转发的行为差异,会直接影响流量迁移的成功。因此前置检查是一项非常重要的步骤。

前置检查项都通过后,接下来就是应用的迁移与流量迁移。
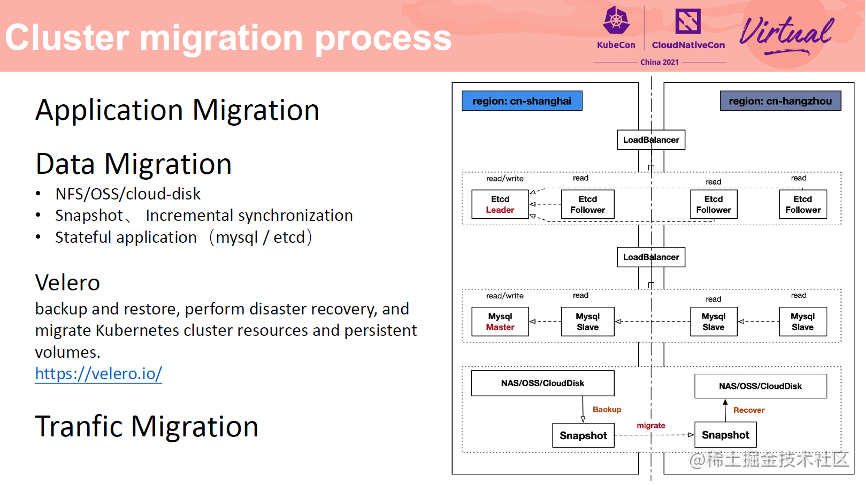
应用的迁移可以通过开源组件 Velero 进行,官方有详细的文档来说明应用的迁移,阿里云也专门为其提交了阿里云相关驱动。这里我们主要介绍一下如何做数据迁移,数据迁移是实现不停机迁移的重要一环,我们会以磁盘存储和有状态应用 MySQL/ETCD 的迁移为例,来说明如何进行数据的迁移。
通常云上的存储主要有 NFS、OSS 对象存储、CloudDisk 云盘等,通常各大云厂商都为磁盘类型的存储提供了完善的快照方法及恢复方法。上图展示了如何将上海 Region 的应用数据迁移到杭州 Region 的方法,对于磁盘存储类型,首先在上海 Region 构建磁盘快照,然后将快照通过云厂商的网络同步到待恢复的地域杭州,然后通过快照恢复功能创建一块磁盘,然后挂在到节点上后应用即可随时使用。
对于自建 MySQL/ ETCD 一类的应用数据,由于其持续读写可能造成潜在的数据不一致的情况,我们可以通过为该应用在目标 Region 构建多个 Slave 副本(或者 quorum 副本),用来进行实时数据同步,当流量低峰期到来的时候,执行主从切换,或者强制选主流程。一旦目标 Region 选主完成,则代表切换完成,可以逐步下线原 Region 的 MySQL 或 ETCD 副本。这就是一个简单的数据迁移流程。
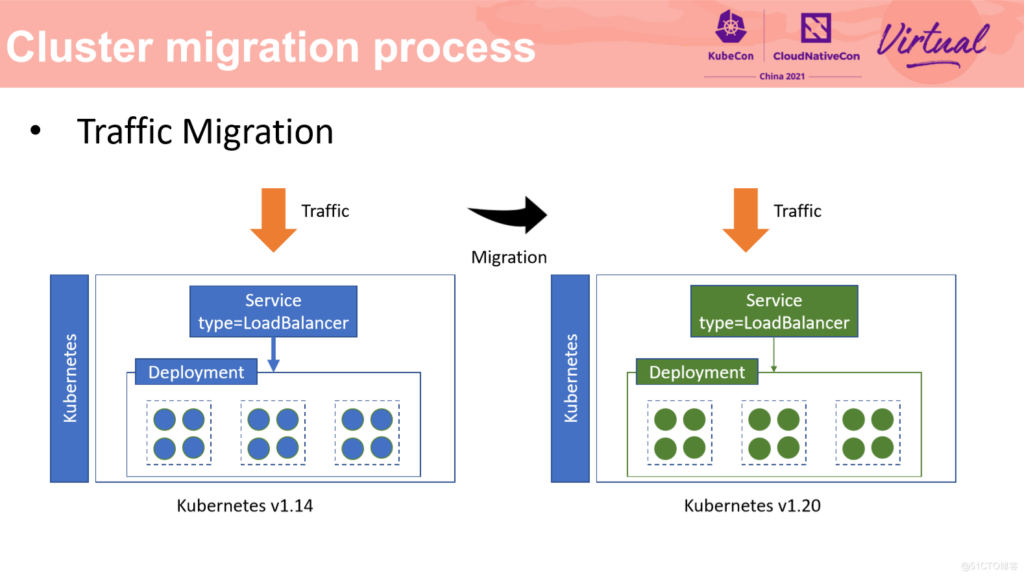
接下来介绍一下流量迁移部分。流量迁移是集群迁移中十分重要的环节。流量迁移是指在业务流量无中断的前提下,将业务流量从一个集群迁移到另一个集群中去。客户端对流量迁移应当完全无感。
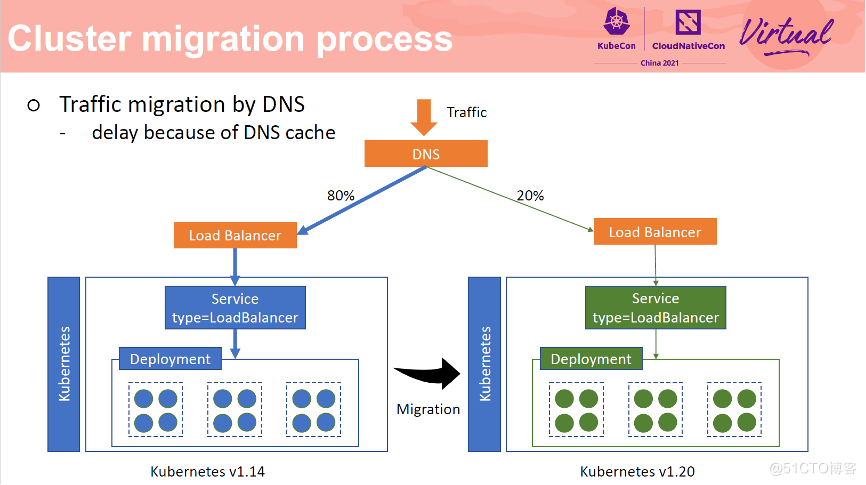
DNS 是实现无损流量迁移的一种方式。分别在两个集群中创建两个 LoadBalancer 类型 Service,然后将两个 SLB 添加到 DNS 后端,基于 DNS 的灰度能力实现流量分发到两个不同的集群中。这种方式较为简单,但是有一个比较大的缺陷,DNS 缓存有过期时间,流量切换后需要等待 30 分钟左右才能生效。当在新集群中进行业务回滚时,这个延迟不可接受的。
另外一种流量迁移方式是基于 Istio 实现的。Istio 方式比较复杂,学习成本比较高。需要新建一个 Istio 集群,并且更改已有的应用部署方式,然后基于 Istio 的灰度能力进行流量迁移。
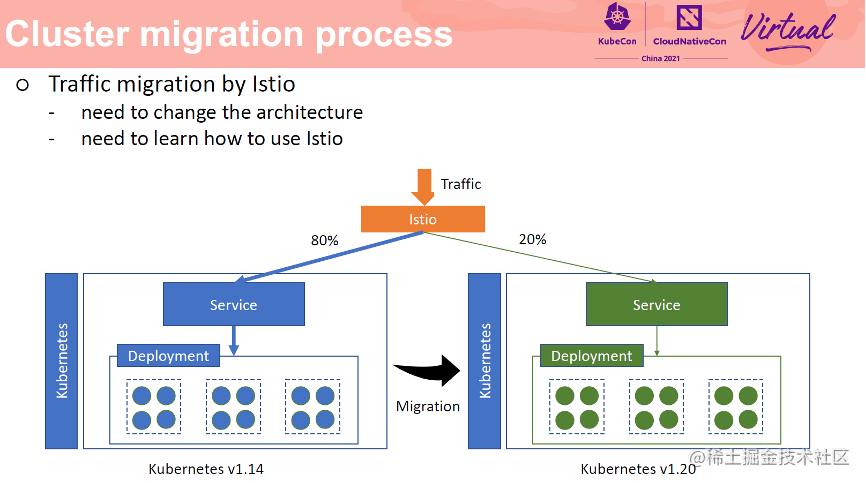
那么有没有一种方式,操作简单又可以实现实时无损流量迁移呢?
如何在零停机的情况下迁移 Kubernetes 集群
为了解决这个问题,我们还得从服务暴露方式入手。LoadBalancer 类型的 Service 实际是通过云上负载均衡器对外部暴露服务的。负载均衡器是由各云服务提供商通过部署在集群中的 controller 创建的,创建出来的负载均衡器的信息会显示在 Service 的 status.loadBalancer 字段中。请求访问云上负载均衡器时,由各云厂商负责将流量重定向到后端 Pod 上。

Cloud Controller Manager(CCM)就是阿里云容器服务部署在 Kubernetes 集群中的 controller,负责对接 Kubernetes 资源及云上基础产品,如 SLB、VPC、DNS 等。对于 SLB,CCM 支持两种流量转发方式,一种是 ECS 模式,一种是 ENI 模式。ECS 模式将 Node IP 和 NodePort 挂载到 SLB 后端,流量经由 SLB 转向 Node,然后经过节点的 kube-proxy 转发至 Pod 上。ENI 模式将 PodIP 及 TargetPort 挂载到 SLB 后端,流量经由 SLB 直接转发到 Pod 上。与 ECS 模式相比,ENI 模式少了一层网络转发,网络性能更好。流量转发模式与 Kubernetes 中网络插件有关,Flannel 网络插件默认为 ECS 模式,Terway 网络插件默认为 ENI 模式。
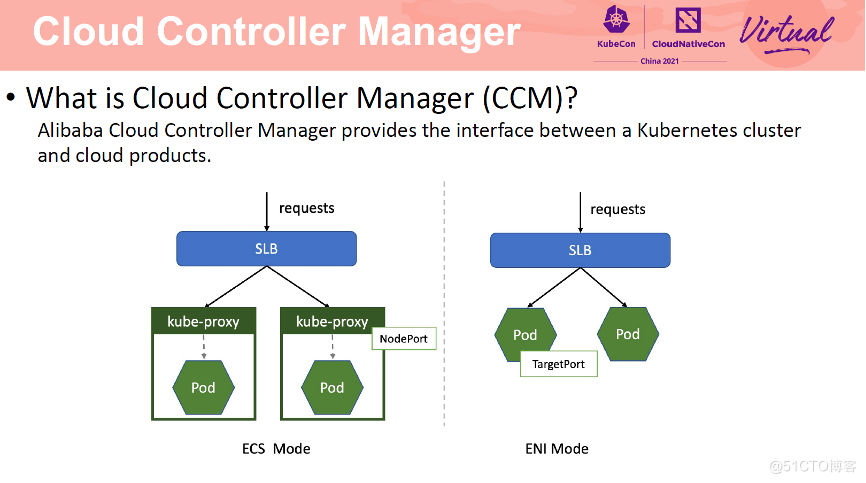
那么 CCM 是如何管理 SLB 的呢?
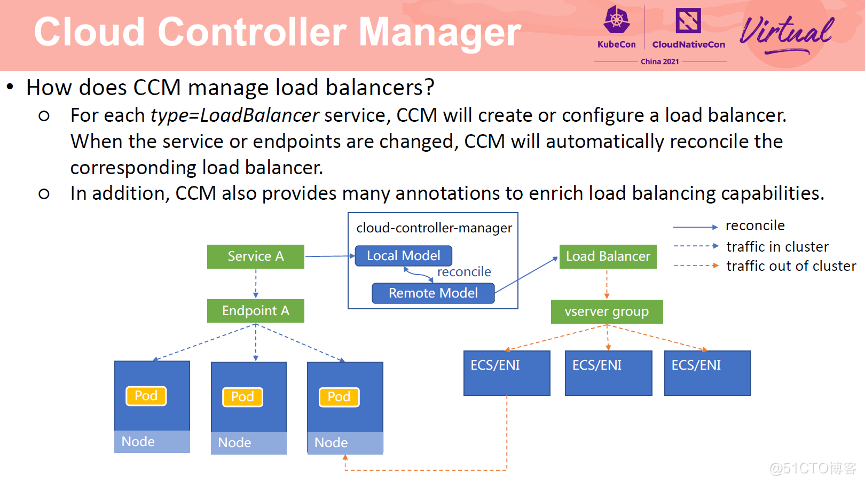
对于 LoadBalancer 类型的 Service,CCM 会为该 Service 创建或配置阿里云负载均衡 SLB。CCM 首先会查询 Kubernetes Service 信息,构建 Local model,然后查询 SLB 信息,构建 Remote model。对比两个 model 的差别,根据 Local model 更新 Remote model,直到两个 model 一致。当 Service 对应的 Endpoint 或者集群节点发生变化时,CCM 会自动更新 SLB 的虚拟服务器组中的后端。此外,CCM 还提供了许多阿里云特定注解,支持丰富的负载均衡能力。
当用户访问 service 时,如果在集群内部,经由 service 转发至 Node,经过 kube-proxy 转发到 Pod。如果访问负载均衡 ip 时,则通过 SLB 后转发至节点 Node 或者 Pod上。
了解 LoadBalancer service 工作原理后,能不能通过 CCM 实现实时无损流量迁移呢?答案是可以的。将两个集群的节点加入到同一个 SLB 的同一个端口中,然后通过修改两个集群所占权重即可实现流量迁移。对于客户端来讲,访问的仍然是以前的 SLB ip 和 port,完全无感。
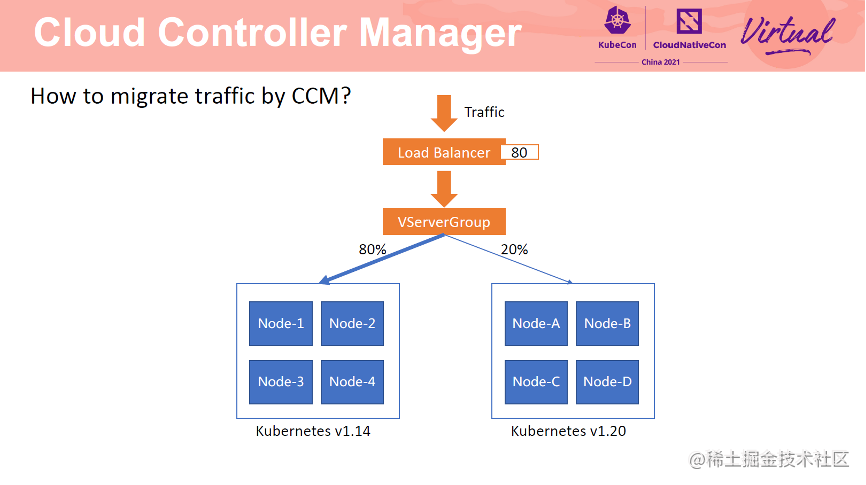
具体操作如下:首先在 1.14 集群中创建一个 Service,指定已有 SLB 及端口,以及端口关联的虚拟服务器组。然后在 1.20 集群中创建一个 Service,指定同样的 SLB、端口及虚拟服务器组。通过 weight annotation 为两个集群设置权重。
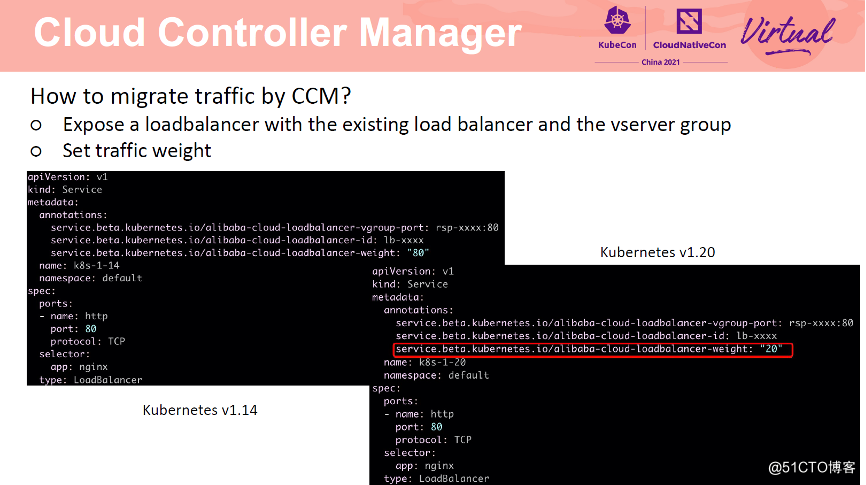
配置完成后,流量转发方式如上图所示。有 80% 的流量转发到 1.14 集群中,20% 的流量转发到 1.20 集群中。
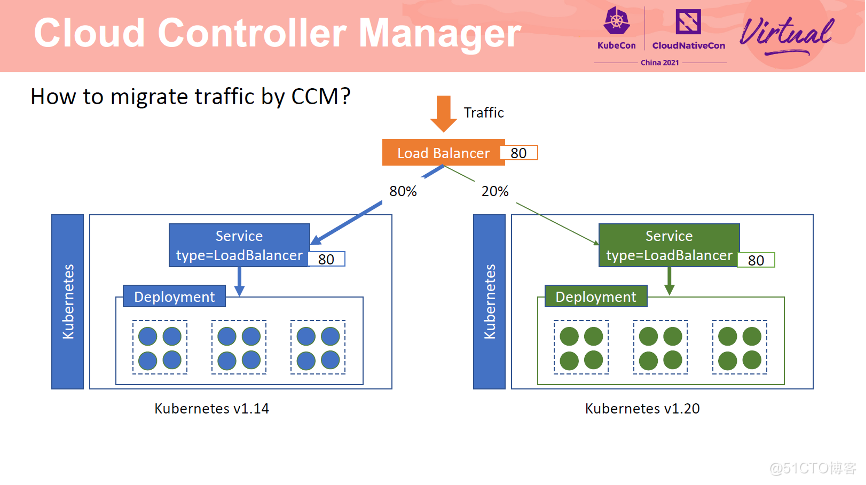
两个集群共用 SLB 的同一个端口。通过修改 Service 中的 weight annotation 可以动态实时修改流向两个集群的流量比例,实现灰度流量迁移。当迁移完成后,从 1.14 集群中删除 Service 即可。
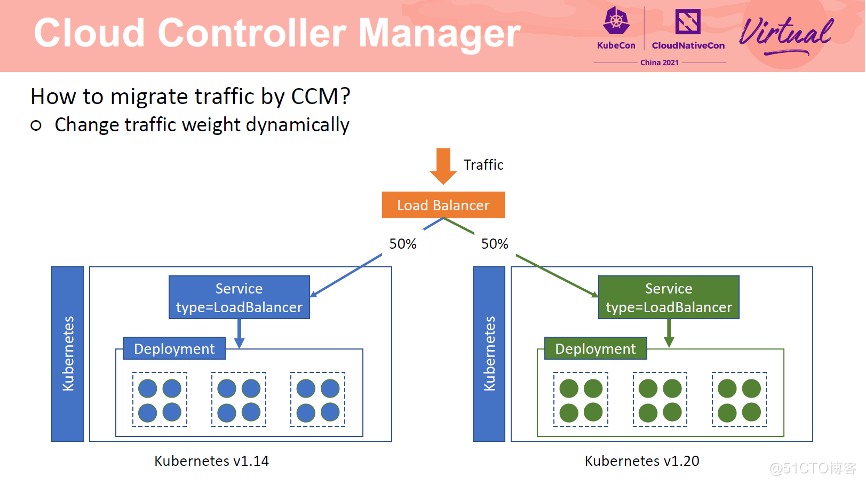
设置权重 annotation 后,如何保证集群内 Pod 负载均衡呢?
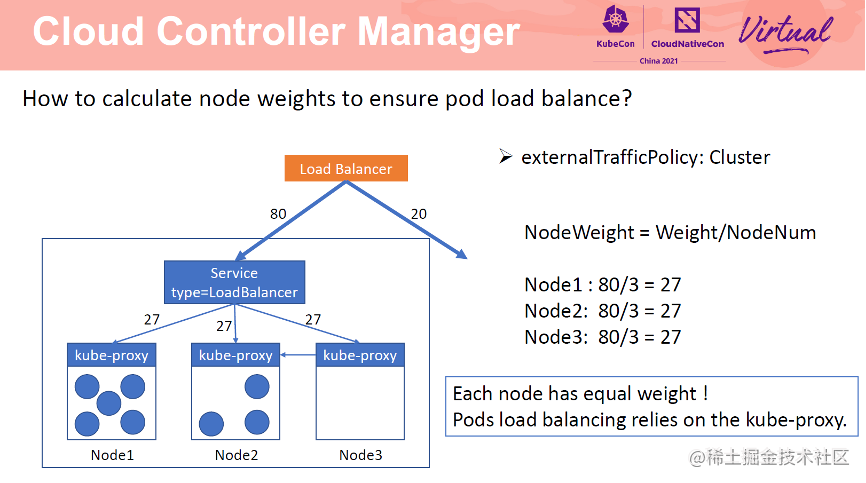
对于 externalTrafficPolicy 为 Cluster 的 service,CCM 会将所有节点加入到 SLB 后端。每个节点的权重为 weight/NodeNum。此时,Node1,Node2,Node3 权重均为 27,但是三个节点上的 Pod 数量并不均衡,那么如何实现 Pod 负载均衡呢?Cluster 模式是依赖 kube-proxy 实现的。在 cluster 模式下,kube-proxy 会将所有 Pod 信息写入到本地的转发规则中,并以轮训的方式向这些 Pod 转发请求。以 Node3 为例,该节点上没有 Pod,当请求发送到 Node3 节点后,kube-proxy 会将请求转发给 Node1 或者 Node2。
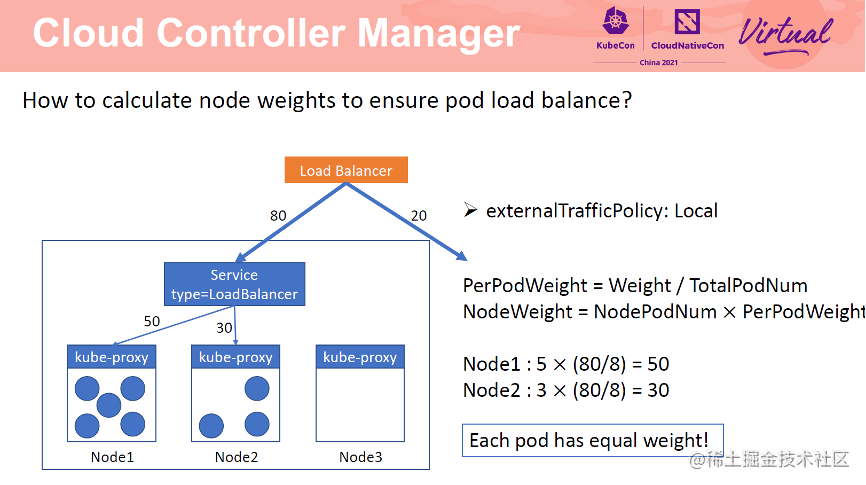
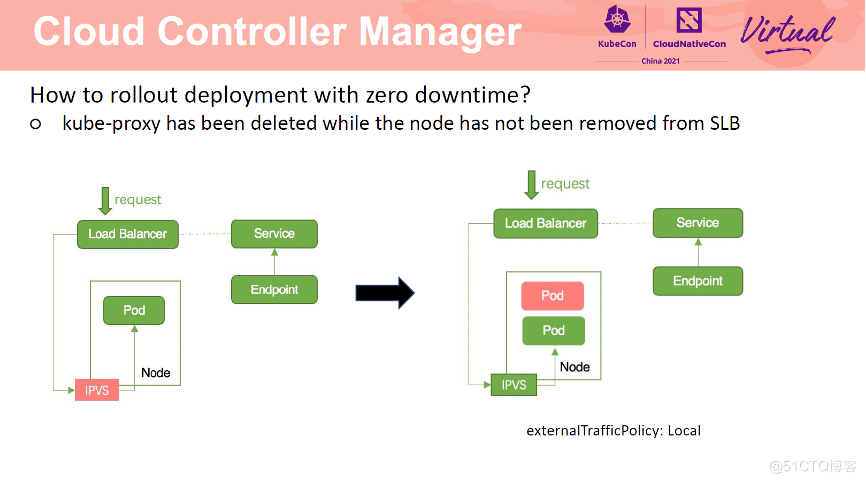
对于 externalTrafficPolicy 为 Local 的 service,CCM 仅会将 Pod 所在节点加入到 SLB 后端。因为如果节点没有 Pod,当请求转发至该节点时,请求会被直接丢弃。Local 模式下,需要先计算每个 Pod 的权重,即 PerPodWeight=Weight/TotalPodNum。节点权重为 NodePodNum*PerPodWeight。Node1 为 50,Node2 为 30。由于每个 Pod 的权重都为 10,因此 Pod 间可以实现负载均衡。
基于 CCM 的流量迁移方案不仅适用于云上集群迁移,还适用于混合云、跨 Region 迁移及跨云迁移场景。以混合云场景为例,客户可以将线下 ECS 加入到 SLB 后端,然后通过设置权重逐步将流量从线下集群迁移到线上集群中,无需进行业务改造,客户端也是完全无感的。
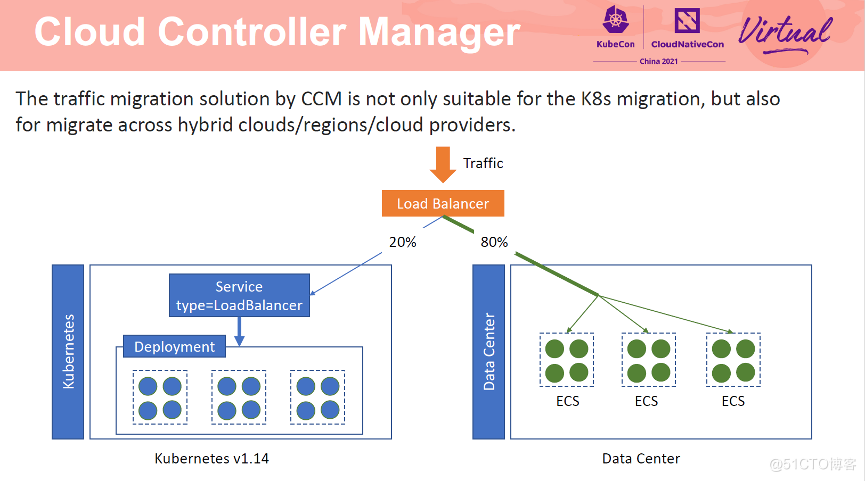
在新集群中测试时不可避免的会遇到应用更新的场景。如果保证应用更新的过程中流量无损呢?
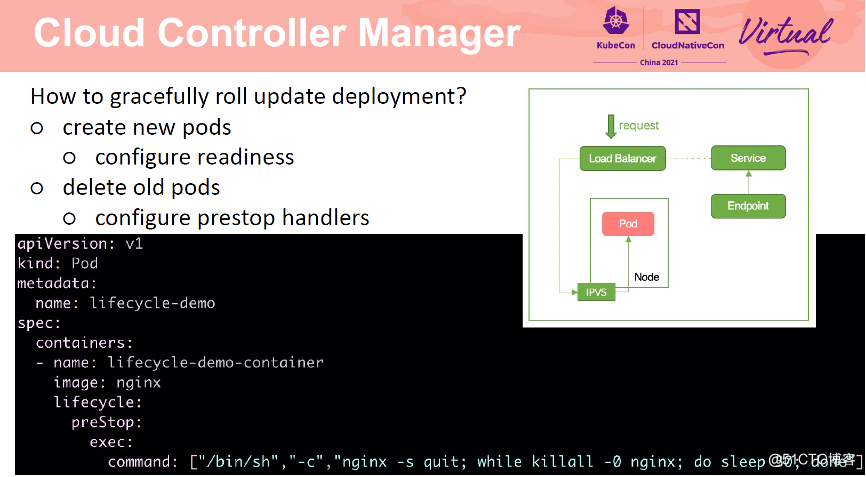
应用更新分为两个步骤,创建新的 Pod,等待 Pod running 后,删除旧的 Pod。新的 Pod 创建成功后,CCM 会将其挂在到 SLB 后端,如果新建的 Pod 无法提供服务,那么请求就会失败。因此,需要为 Pod 添加就绪检测。仅当 Pod 可以对外服务时,才将其加入到 SLB 后端。在删除 Pod 时也会遇到同样的场景。因为 Pod 删除和从 SLB 后端移除 Pod 是异步进行的,如果 Pod 以及删除,但是还未从 SLB 后端移除,就会出现请求转发到后端,但是无 Pod 处理导致请求失败的情况。因此需要为 Pod 添加 prestop hook。
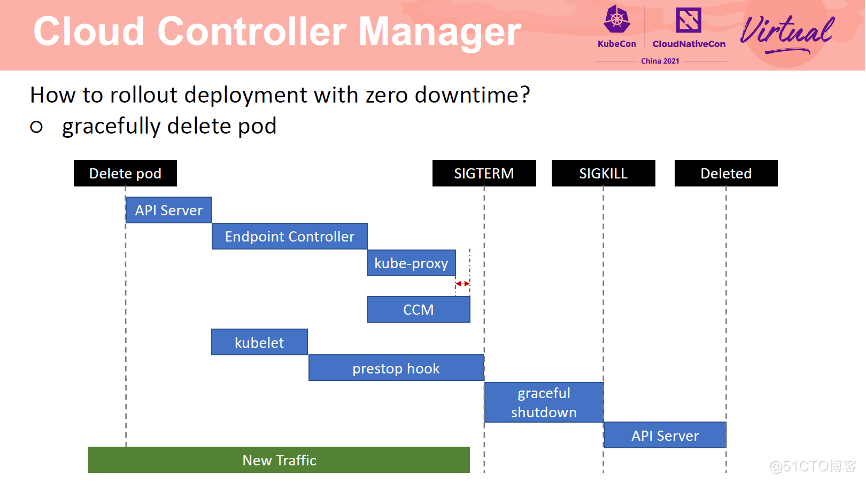
Pod 优雅退出过程如上图所示。首先 kubelet delete pod,然后 endpoint controller 更新 endpoint。更新完毕后,kube-proxy 移除节点转发规则。CCM 检测到 endpoint 更新事件后,从 SLB 后端移除 Pod。在apiserver 删除 Pod 时,kubelet 同时开始删除 Pod 逻辑,触发 Pod prestop。在 prestop 结束后发送 sigterm 信息。在整个 Pod 优雅退出过程中,直到 CCM 从 SLB 后端移除 Pod 之前一直会有新的流量进入。
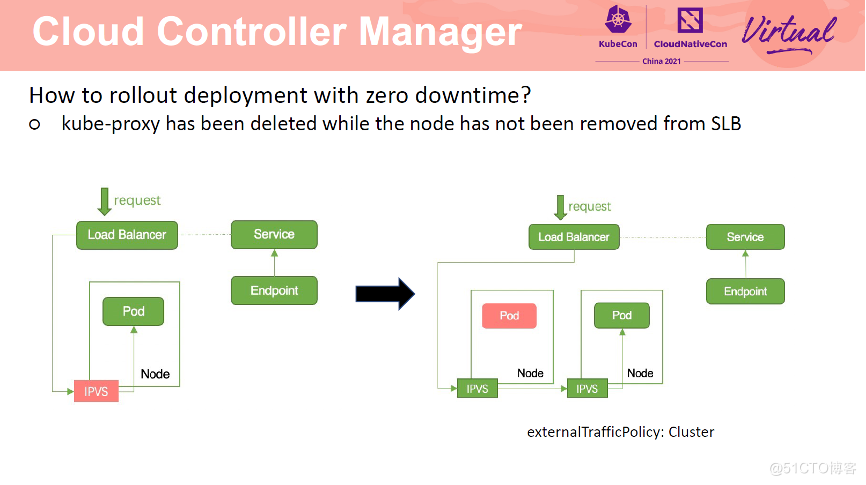
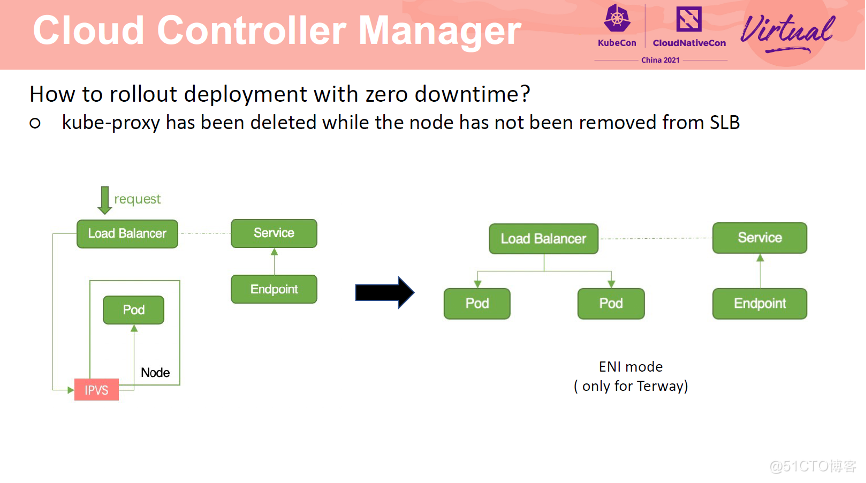
由于 CCM 与 kube-proxy 是异步进行的,因此会出现 SLB 还未移除 Pod,kubeproxy 已经将节点转发规则清理的情况。此时,请求进入 SLB 后,转发至 Node上,由于 kube-proxy 已经将路由规则清理了,所以该请求无法处理。将 service 改为 cluster 模式可以解决这一问题。如果 Service 一定需要为 local 模式,那么需要保证一个节点上有多个 Pod。也可以通过设置 Service 为 eni 模式解决这一问题。
总结来说,集群迁移可以分为如下三个步骤,前置检查、应用迁移及流量迁移三个步骤。前置检查需要检查不同集群间 api/Node label 等兼容性,应用迁移可以使用开源工具进行,基于 CCM 则可以实现实时无损流量迁移。
本次分享到此结束,谢谢。
原文地址:http://blog.itpub.net/69953029/viewspace-2851044/